Domain-Specific Accelerator Design
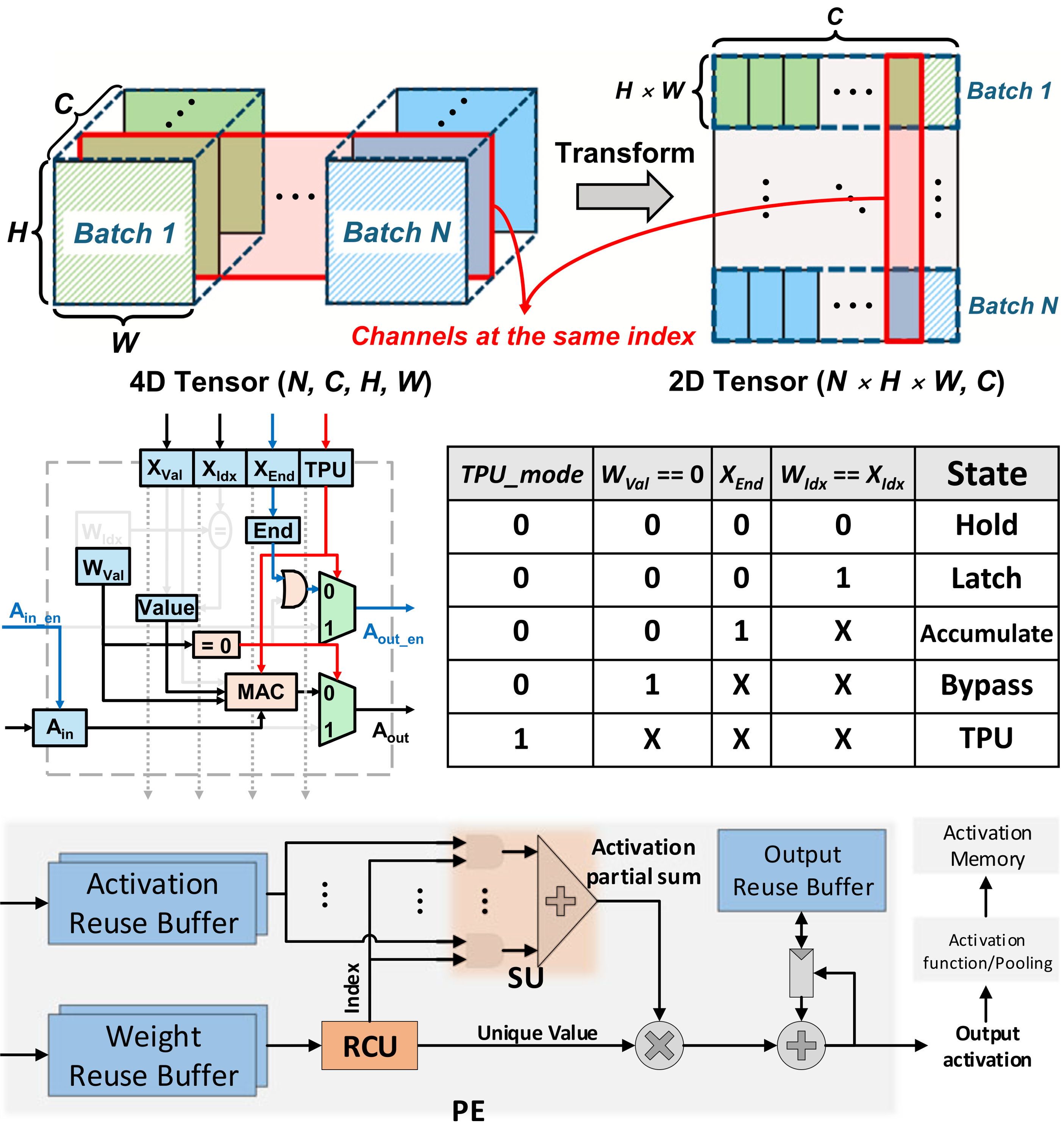
Sparsity-aware PE architecture
-
Summary:
- Multi-window dataflow architecture for selective weight update
- Redundancy Censoring Unit (RCU)-based PE architecture
-
Reference:
- Jaekang Shin, Seungkyu Choi, Yeongjae Choi, and Lee-Sup Kim, "A Pragmatic Approach to On-device Incremental Learning System with Selective Weight Updates," ACM/IEEE Design Automation Conference (DAC), 2020.
- Kangkyu Park, Seungkyu Choi, Yeongjae Choi, and Lee-Sup Kim, "Rare Computing: Removing Redundant Multiplications from Sparse and Repetitive Data in Deep Neural Networks," IEEE Transactions on Computers, Apr. 2022.
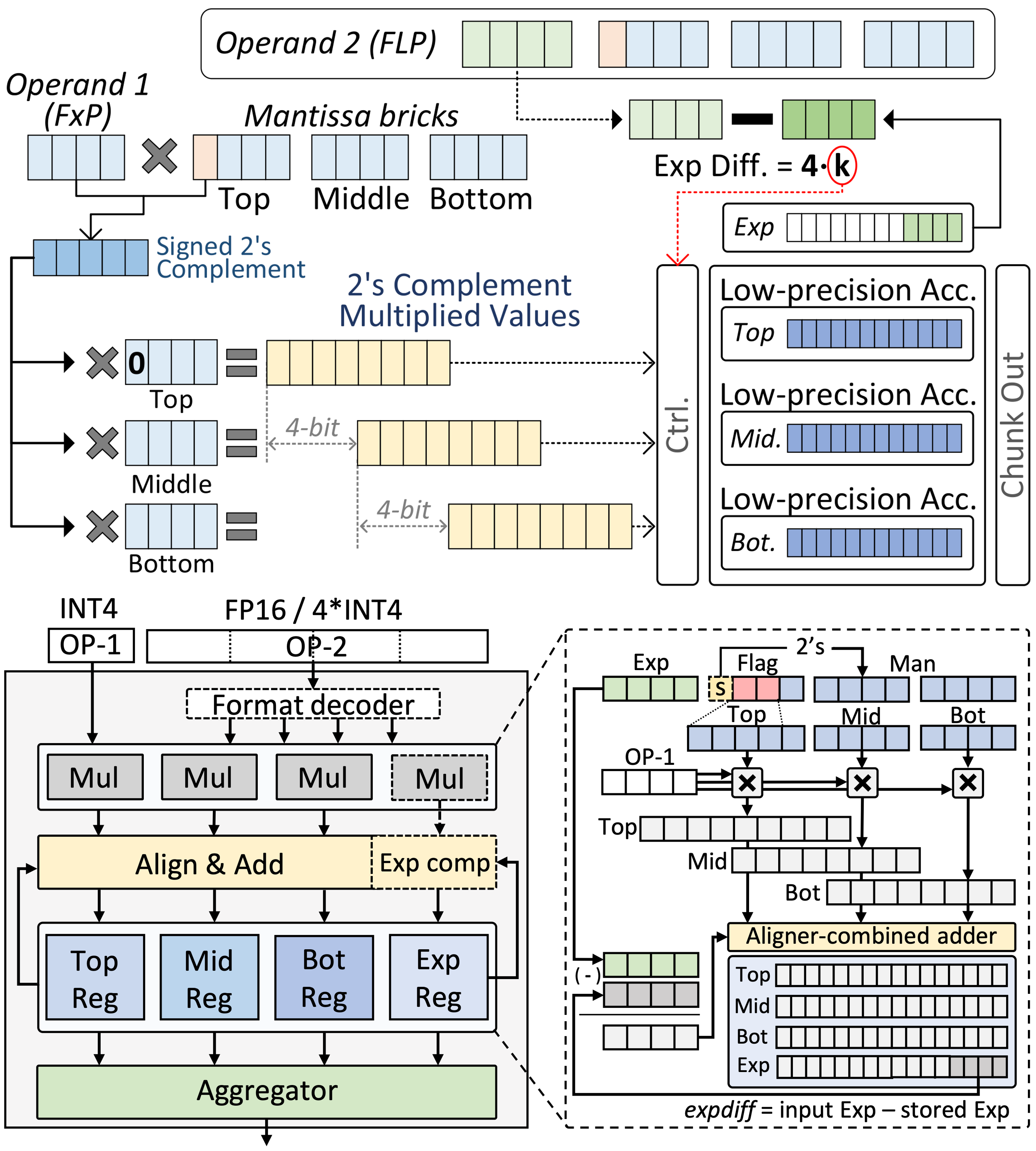
Mixed-precision Processing units
-
Summary:
- We design unified hardware architectures to eliminate computational and memory inefficiencies across the entire AI lifecycle. Our research centers on flexible, mixed-precision processing units capable of seamlessly supporting heterogeneous data types—from standard formats to advanced block-scaled representations for Large Language Models. By dynamically adapting numerical precision to workload demands, we develop scalable accelerators that maximize throughput and energy efficiency without compromising model accuracy.
-
Reference:
- Seungkyu Choi, Jaekang Shin, and Lee-Sup Kim, "A Deep Neural Network Training Architecture with Inference-aware Heterogeneous Data-type," IEEE Transactions on Computers, May 2022.
- Jongwoo Park, Hyeonsung Kim, Jiyun Han, and Seungkyu Choi, "A Mixed-Precision Architecture for Efficient DNN Training with Inference-aware Data-type," ACM/IEEE Design Automation Conference (DAC), 2025.
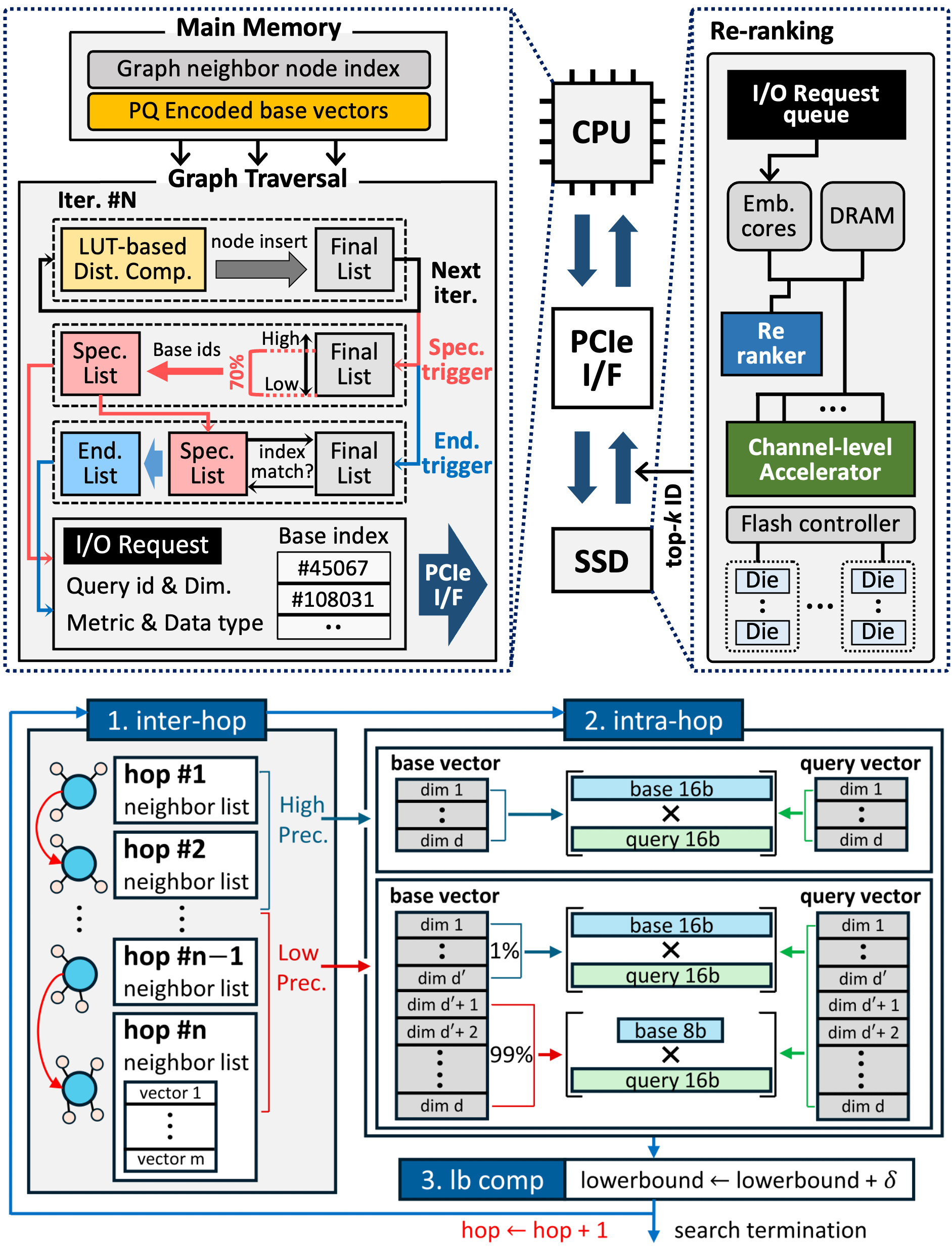
Memory-Efficient Architecture for Vector Search
-
Summary:
- We specialize in architecting scalable hardware-software solutions to eliminate memory and I/O bottlenecks in massive-scale AI retrieval systems. Our research bridges CPU, custom ASIC, and in-storage processing to accelerate vector similarity search for large language models. By pioneering novel data quantization schemes and speculative execution models, we deliver ultra-fast, high-recall vector databases tailored for modern AI workloads.
-
Reference:
- Seongjoon Cho, Junyoung Park, Donghyun Kang, Moohyeon Nam, Hongchan Roh, Moo-Kyoung Chung, Se-Hyun Yang, and Seungkyu Choi, "LOHA: A Latency-Optimized CPU-Storage Hybrid Architecture for Billion-Scale Graph-based Vector Similarity Search," ACM/IEE Design Automation Conference (DAC), 2026.
- Seongjoon Cho, Junyoung Park, Donghyun Kang, Moohyeon Nam, Hongchan Roh, Moo-Kyoung Chung, Se-Hyun Yang, and Seungkyu Choi, "Q-VESA: Accelerating Quantization-Aware Vector Search for Fast Retrieval in Prompt Engineering," IEEE Transactions on Computers, Feb. 2026.
Hardware-Efficient Data Formats
-
Summary:
- a novel 8-bit PTQ data format designed for various DNNs
- Leveraging the dynamic configuration of exponent and fraction bits derived from Posit data format, but demonstrates enhanced decoding efficiency
-
Reference:
- Nguyen-Dong Ho, Gyujun Jeong, Cheol-Min Kang, Seungkyu Choi, and Ik-Joon Chang, "MERSIT: A Hardware-Efficient 8-bit Data Format with Enhanced Post-Training Quantization DNN Accuracy" ACM/IEEE Design Automation Conference (DAC), 2024.